.NET CORE 下通过 SmtpClient 发送邮件
通过本文你可以实现:使用 .NET SmtpClient 来发送邮件
- 基础使用:仅含有邮件内容,无附件;
- 发送含有附件的邮件;
- 以及抄送等功能。
通过本文你可以实现:使用 .NET SmtpClient 来发送邮件
Summary:
物理excel文件硬编码即可。环境说明:
VS 2019
通过本文你可以获得如何用 autofac 替换 .NET CORE(2.1,3.1) 默认 IOC 容器。
每个依赖一个实例(Instance Per Dependency) (默认) ----InstancePerDependency()
单一实例(Single Instance) 单例 ----SingleInstance()
每个生命周期作用域一个实例(Instance Per Lifetime Scope)----InstancePerLifetimeScope()
每个匹配的生命周期作用域一个实例(Instance Per Matching Lifetime Scope)----InstancePerMatchingLifetimeScope()
每个请求一个实例(Instance Per Request) asp.net web请求----InstancePerRequest()
每次被拥有一个实例(Instance Per Owned) ----InstancePerOwned()
反射
使用实例
lambda 表达式
示例代码说明:
MAC OS 中 iterm2 结合 zsh 对于开发而言,日常操作相当友好,同时对 MAC OS 下的 VSC 也相当友好,基本零配置。
在 windows 环境下,除了通过 WSL 安装 ZSH 嵌入 VSC 外,如果你平时有使用 cmder,那么可以直接将 cmder 集成到 VSC 中。
最终在 VSC 终端的效果图:
日常 CMDER 效果如图下:
我已经集成 zsh,并设置了 cmder 一些快捷键跟 iterm2 保持一致,你可以根据自己的需要来定制自己的 cmder。
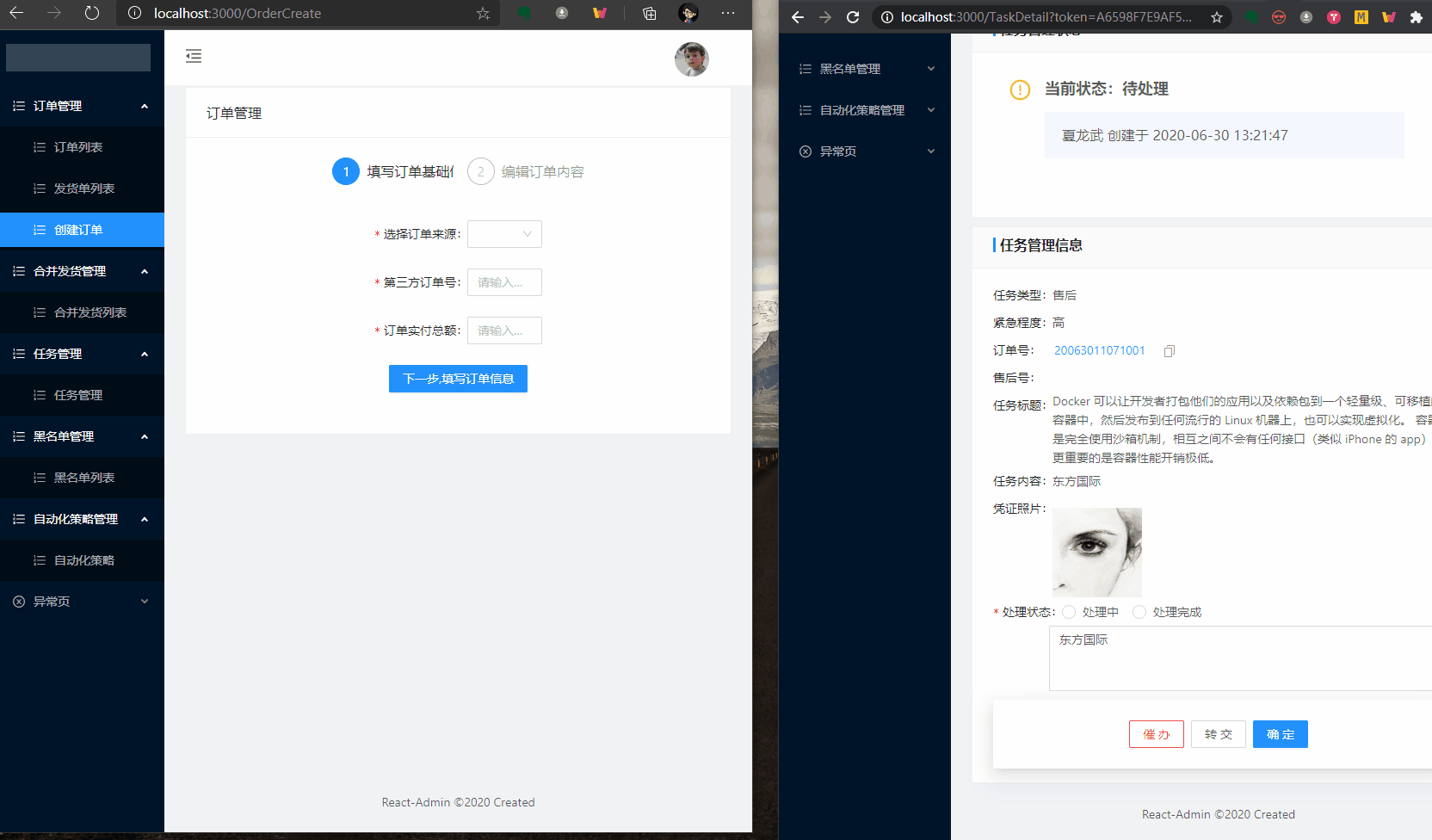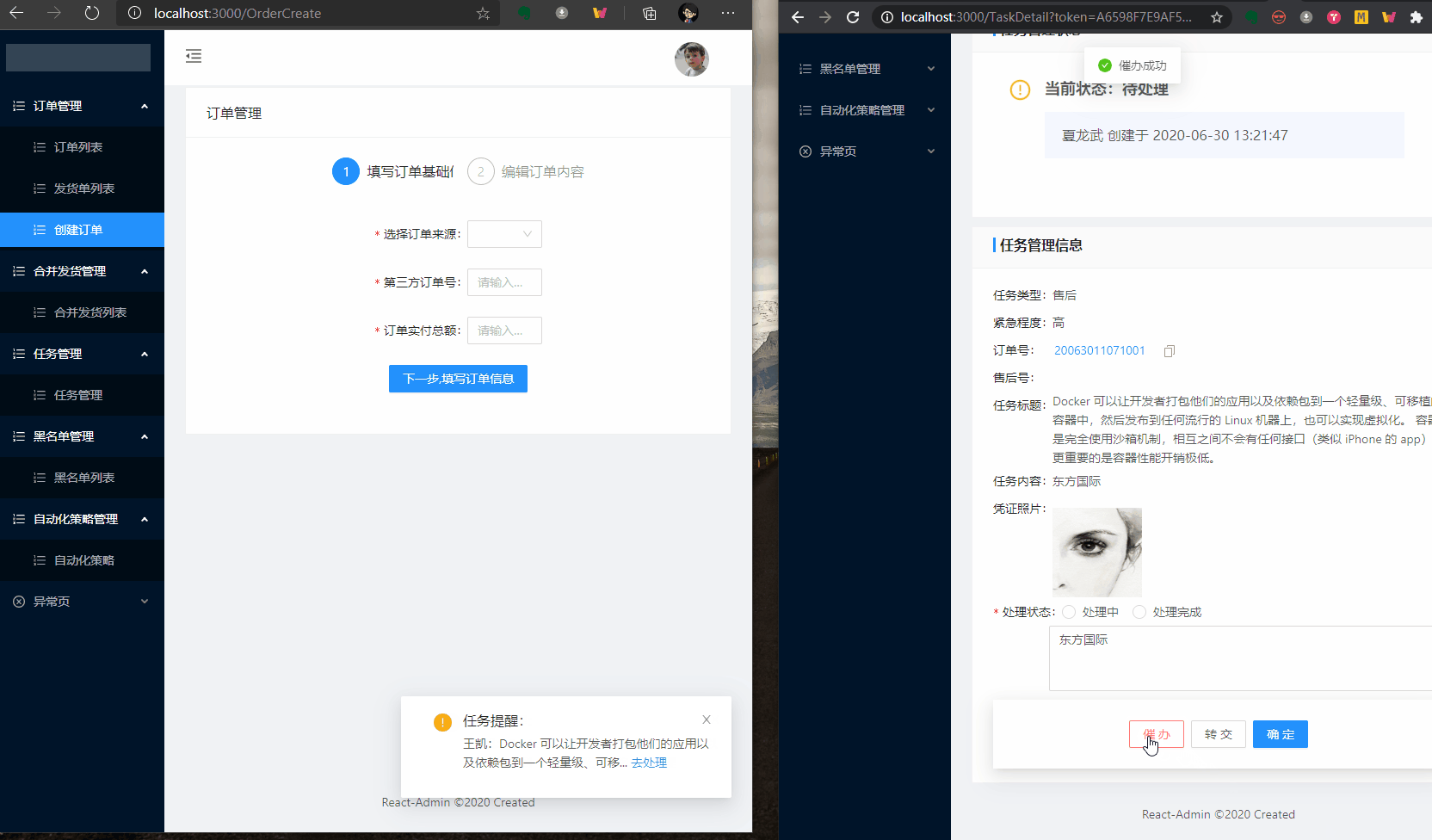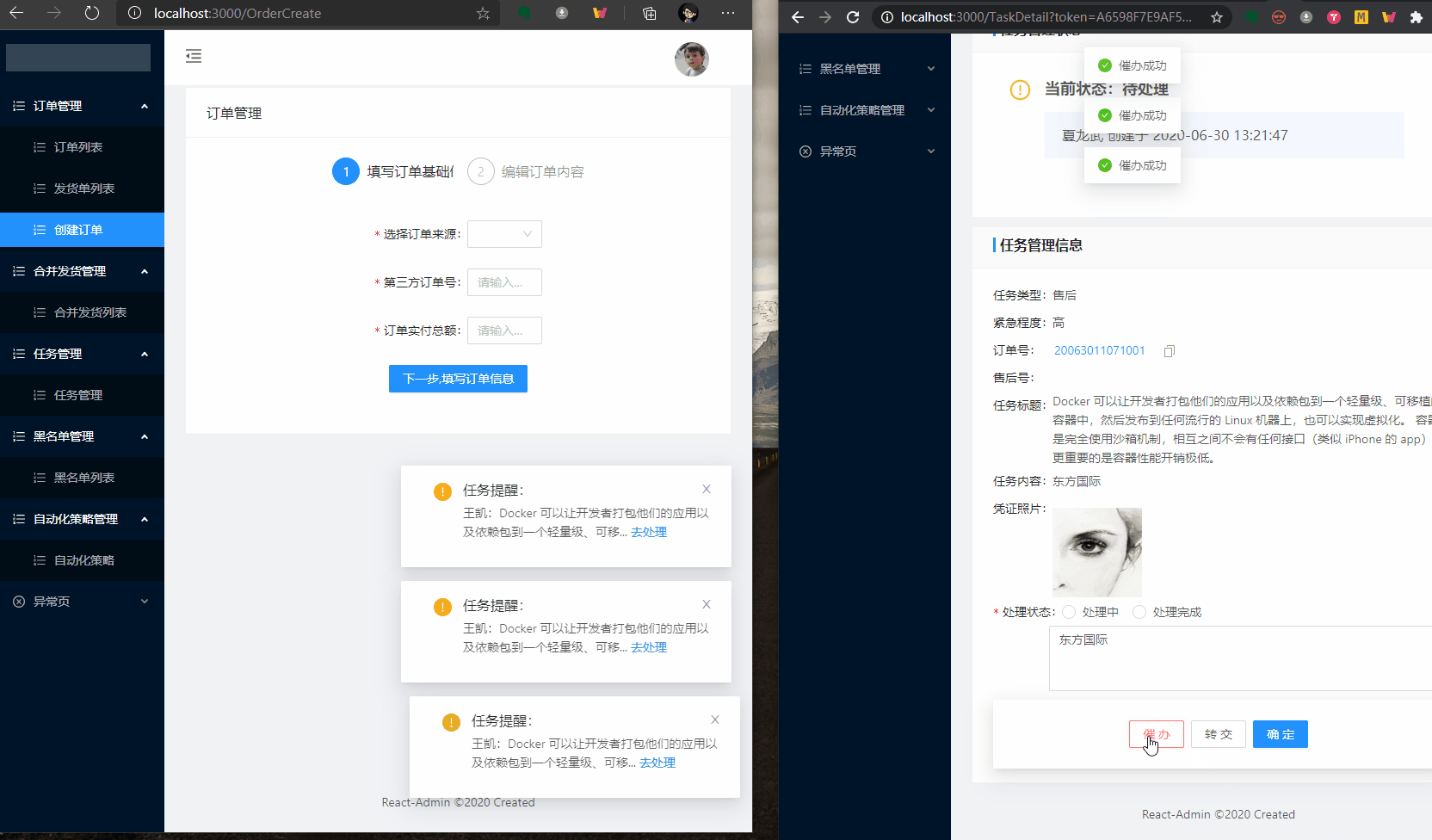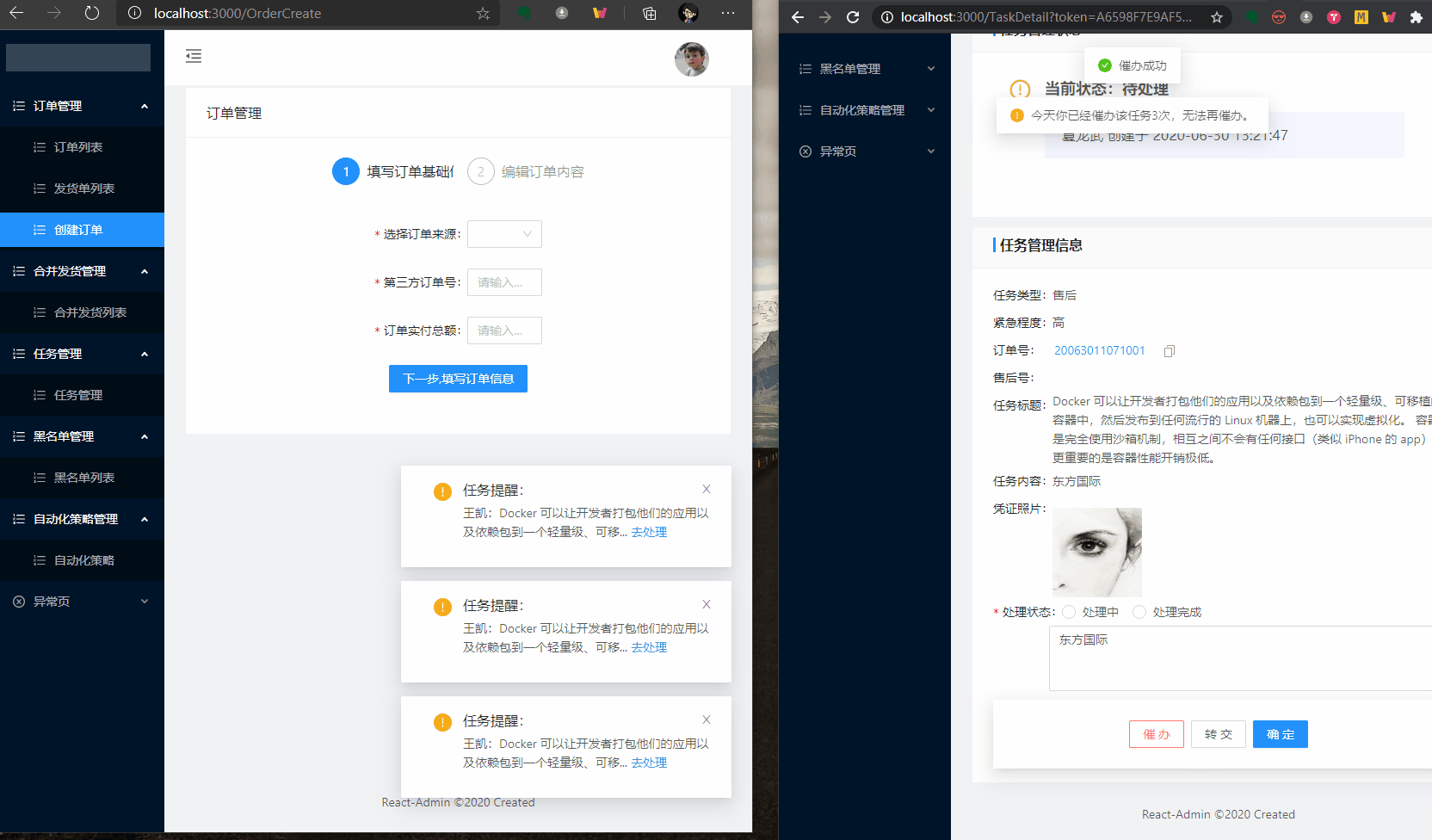
本文对应的环境:React + ANTD + .NET CORE WEB API + SignalR
- 本文示例部分分为
前端和后端两部分
效果图:
用到的包和版本如下:

前端组件代码如下:
以下示例基于 Quartz.Net 3.0.7(在最新的 3.1-beta2 中已经包含了支持 Microsoft DI 的方法)
在 worker service 中,通过官网示例,会发现 quartz.net 并未生效,究其原因系 DI 未注入导致,原生 quartz.net(3.0.7)是通过 CreateInstance 来创建实例的,本文旨在解决在 Worker Service、Console 中使用 quartz.net 无效的问题。
项目结构如下:
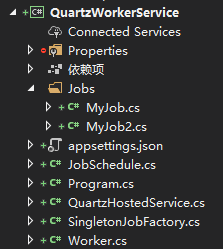
JobSchedule.cs
用来配置 Job,如果需要更多配置,可以扩展该类。
1 | public class JobSchedule |
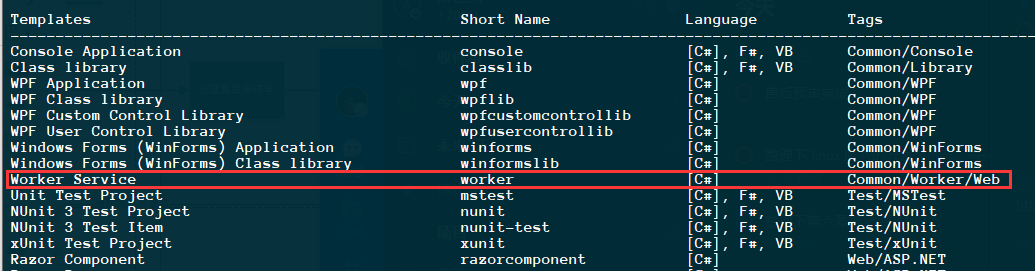
.NET CORE 3.1 提供了 worker service 这么一个模板,可以方便开发者来创建”windows 服务程序“(同样可发布于 linux)。本篇以 centos 7.6 为发布环境,简要说明如何使用 worker service 来创建服务,并部署发布到 centos 中。
你可以通过以下命令来查看本地安装的 .net core 环境:
1 | dotnet --version # 笔者为 3.1.301 |
你可以通过以下命令来查看是否含有 worker service 模板:
1 | dotnet new -l |
你可以通过如下命令在当前解决方案中安装:
本系列博文是“伪”官方文档翻译(更加本土化),并非完全将官方文档进行翻译,而是在查阅、测试原始文档并转换为自己真知灼见后的“准”翻译。有不同见解 / 说明不周的地方,还请海涵、不吝拍砖 :)
官方文档见此:https://www.elastic.co/guide/en/elasticsearch/client/net-api/current/introduction.html
本系列对应的版本环境:ElasticSearch@7.3.1,NEST@7.3.1,IDE 和开发平台默认为 VS2019,.NET CORE 2.1
ES 中的某些API参数可以接受多个 JSON 数据结构,例如,搜索请求时对 source 过滤可以接受:
bool:可以通过布尔值来禁用 _source 检索。
string、string[]:可以使用字符串来设定通配符,以此来控制返回 _source 中的哪些部分。
object:一个包含 includs 和 excluds 属性的对象,来分别控制需要在 _source 中需要“包含”和“排除”的部分。
在 NEST 中,可以使用 Union<First,Second> 类型。
Union<TFirst,TSecond>具有隐式运算符,可从 TFirst 或 TSecond 的实例转换为Union<TFirst,TSecond> 的实例:
1 | Union<bool, ISourceFilter> sourceFilterFalse = false; |
本系列博文是“伪”官方文档翻译(更加本土化),并非完全将官方文档进行翻译,而是在查阅、测试原始文档并转换为自己真知灼见后的“准”翻译。有不同见解 / 说明不周的地方,还请海涵、不吝拍砖 :)
官方文档见此:https://www.elastic.co/guide/en/elasticsearch/client/net-api/current/introduction.html
本系列对应的版本环境:ElasticSearch@7.3.1,NEST@7.3.1,IDE 和开发平台默认为 VS2019,.NET CORE 2.1
在“查询/过滤”的时候支持使用日期类型的数学表达式。表达式以“锚定”日期开始,该日期可以是现在,也可以是以“||”结尾的日期字符串。它后面可以是一个数学表达式,支持 +,- 和 /(四舍五入)。支持的单位有:
y (year)
M (month)
w (week)
d (day)
h (hour)
m (minute)
s (second)
ES 中的 Date Math。
使用 DateMath 提供的静态方法:
1 | Expect("2020-01-23T00:00:00").WhenSerializing(Nest.DateMath.Anchored(new DateTime(2020,01, 23))); |
本系列博文是“伪”官方文档翻译(更加本土化),并非完全将官方文档进行翻译,而是在查阅、测试原始文档并转换为自己真知灼见后的“准”翻译。有不同见解 / 说明不周的地方,还请海涵、不吝拍砖 :)
官方文档见此:https://www.elastic.co/guide/en/elasticsearch/client/net-api/current/introduction.html
本系列对应的版本环境:ElasticSearch@7.3.1,NEST@7.3.1,IDE 和开发平台默认为 VS2019,.NET CORE 2.1
在 ES 的 GEO 相关查询中,你会使用到“距离”这个概念,Nest 提供了 Distance 类来帮助你创建“距离”。
1 | var unitComposed = new Distance(25); |
也可以使用指定距离单位的字符串,如下:
1 | Expect("25m") |