Elasticsearch.Nest 教程系列 6-1 分析:Writing analyzers | 编写分析器
本系列博文是“伪”官方文档翻译(更加本土化),并非完全将官方文档进行翻译,而是在查阅、测试原始文档并转换为自己真知灼见后的“准”翻译。有不同见解 / 说明不周的地方,还请海涵、不吝拍砖 :)
官方文档见此:https://www.elastic.co/guide/en/elasticsearch/client/net-api/current/introduction.html
本系列对应的版本环境:ElasticSearch@7.3.1,NEST@7.3.1,IDE 和开发平台默认为 VS2019,.NET CORE 2.1
ES 中的“分析”是指将文本(如任何电子邮件的正文)转换为 tokens 或 terms 的过程,这些 tokens 或 terms 被添加到倒排索引中以进行搜索。分析是由分析器执行的,该分析器可以是内置分析器,也可以是自定义的分析器。
分词器由 3 部分组成:
-
Character Filters:处理原始文本,如去除 html。
- 一般有 0 个或多个
-
Tokenizer:按照规则切分为单词。
- 一般只有 1 个
-
Token filter:加工切分后的单词,如转小写、删除停用词,增加同义词等。
- 一般有 0 个或多个
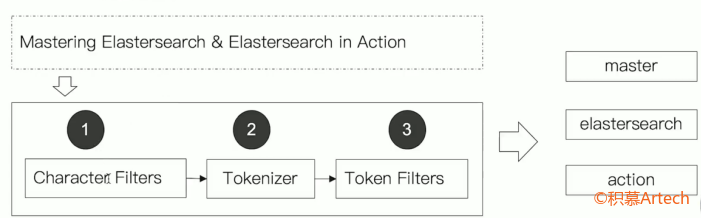
- 一般有 0 个或多个
在字段上指定分析器
一般在创建索引或者使用 Put Mapping API 添加新字段的时候,可以在 text 数据类型的字段上指定分析器。
-
但是你不能在一个已经存在的字段上增加分析器,因为这会导致在搜索的时候期望结果不正确。
-
另外如果你修改了现有的字段,则你需要对数据进行 reindex。
eg:指定 Elasticsearch中 的 name 字段(映射到 Project 类的 Name 小户型)在创建索引时指定使用空白分析器:
1 | var createIndexResponse = _client.Indices.Create("my-index", c => c |
配置内置分词器
可以通过配置修改默认分词器的行为,如可以通过配置“标准分词器”以支持包含停用词过滤器的停用词列表。
配置内置分词器需要基于内置分词器来进行的:
1 | var createIndexResponse = _client.Indices.Create("my-index", c => c |
创建索引的设定信息如下:
1 | { |
创建自定义的分词器
假设有以下类:
1 | public class Question |
-
Body 保存的是 HTML 并且包含一些源码关键字。
现在希望能够使用“C#”来搜索相关文档,但如果使用标准分词器的话,会把“C#”分析为“c”,根我们的预期不一致了。通过以下方式可以自定义一个分词器:
1 | var createIndexResponse = _client.Indices.Create("questions", c => c |
以上分词器,在对分词进行分析的时候会经过以下流程:
-
删除 HTML 标签。
-
分别映射“C#”和“c#”为“CSharp”和“csharp”(# 号不会被 tokenizer 删除。)
-
使用标准分词器进行分词。
-
使用标准分词过滤器进行过滤。
-
把所有 tokens 转换成小写。
-
移除所有停用词。
全文查询时同样会对查询输入进行相同的分析。
在索引和搜索时使用不同的分词器
在平时的业务开发中,我们可能会希望索引(添加)文档和搜索文档时使用不同的分词器,通过以下方式可以实现:
1 | var createIndexResponse = _client.Indices.Create("questions", c => c |
-
另外,搜索分词器还可以在每个查询上进行单独指定。
-
关于 ES 中的分词器,可以见此。