Elasticsearch.Nest 教程系列 8 聚合:Writing Aggregations | 使用聚合
本系列博文是“伪”官方文档翻译(更加本土化),并非完全将官方文档进行翻译,而是在查阅、测试原始文档并转换为自己真知灼见后的“准”翻译。有不同见解 / 说明不周的地方,还请海涵、不吝拍砖 :)
官方文档见此:https://www.elastic.co/guide/en/elasticsearch/client/net-api/current/introduction.html
本系列对应的版本环境:ElasticSearch@7.3.1,NEST@7.3.1,IDE 和开发平台默认为 VS2019,.NET CORE 2.1
可以简单将 ES 中的聚合和 Sql server 中的“聚合函数(如 SUM,COUNT 等”)相关联。聚合可以嵌套,通过聚合可以找出某个字段的最大值,最小值,平均值,以及对字段进行求和操作等复杂数据的构建。
另外,ES 还提出了 buckets(桶) 这个概念,你可以简单理解为相当于是 Sql server 中的分组(GROUP BY),即在 ES 中的称 GROUP BY 为“分桶”。
关于 Elasticsearch 中的聚合说明,可以见此。
编写聚合
Nest 提供了 3 种方式来让你使用聚合:
-
通过 lambda 表达式的方式。
-
通过内建的请求对象 AggregationDictionary。
-
通过结合二元运算符来简化 AggregationDictionary 的使用。
假设有以下 Project 类:
1 | public class Project |
三种方式的请求命令见下方:
1 | POST /project/_search?typed_keys=true |
lambda 方式
通过 lambda 表达式来使用聚合是简洁的方式
1 | var searchResponse = _client.Search<Project>(s => s |
响应结果如下:
1 | { |
一般进行聚合查询的时候,并不需要 _source 的东西,所以你在进行聚合查询是,可以在查询语句上指定 size=0,这样就只会返回 聚合 的结果,方式如下:
1 | var searchResponse = _client.Search<Project>(s => s |
调整后的返回结果如下:
1 | { |
通过内建对象 AggregationDictionary
以下代码的效果和通过 lambda 表达式的效果一样
1 | var searchRequest = new SearchRequest<Project> |
-
这种方式在可读性上较差。
通过结合二元运算符来简化 AggregationDictionary 的使用
通过二元运算符,可以让代码的可读性更高,以下代码等效于上方:
1 | var searchRequest = new SearchRequest<Project> |
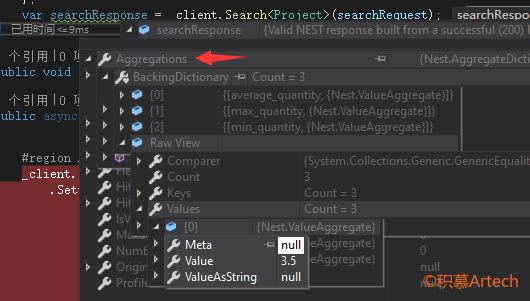
获取响应结果
通过使用响应模型的 .Aggregations 属性,可以让你得到聚合的结果,如下:
保留关键字
在使用聚合功能的时候,需要避免跟 ES 保留关键字冲突,如以下关键字(包含但不限于):
-
“score”
-
“value_as_string”
-
“keys”
-
“max_score”